
Editorial
Introducing Who’s In the Know: The Privacy Pulse Report
March 27, 2024
Editorial
There are already many tools available which aim to prevent the kinds of tracking we have described elsewhere.
In general, these tools act as browser extensions which monitor network traffic and intervene when tracking is detected, i.e. blocking unique identifiers (UIDs) in transmission.
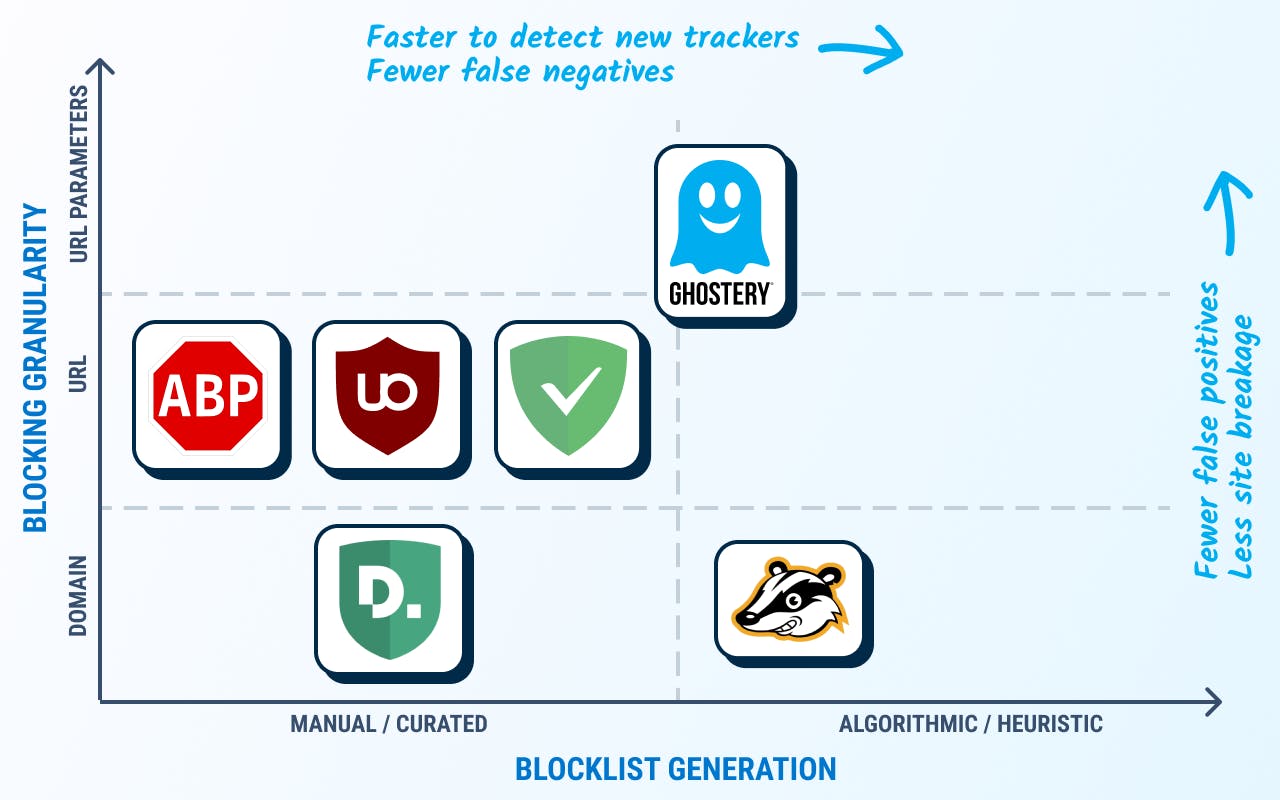
The mechanism they use to block or sanitize UIDs can be categorized into two groups:
Blocklist-based methods have several shortcomings:
Blocking requests is very coarse grained and can easily break site functionality. Overly broad blocking rules may block many requests which are of no privacy risk.
On the other hand, exceptions made to prevent site breakage may then allow some privacy leaks. For example, the Facebook like button is still allowed when using the EasyPrivacy blocking list, and there are many other such exceptions.
Blocklists bestow significant power to their curators. With blocking browser extensions being used ever more (over 40% of users for some market segments), those who write the block list would have the power to cut off a significant proportion of a company’s traffic — deservedly or not.
Heuristic approaches like Privacy Badger are limited by just having local knowledge. In many cases we will not know if data sent is unique to us until we have tested it in another browser and seen a different value, like in the fingerprinting example in the previous post.
Thus, some kind of collaboration is required between users to determine what data is safe, and what is not – and this is the method Ghostery’s anti-tracking uses.
As we outlined in the previous section, blocklists have several drawbacks, and we did not want such an aggressive system. Likewise, relying on purely local evaluation of whether data is a UID or not has significant limitations.
Therefore, we designed a system which combines local with global evaluation of tracking data. It is also designed to be conservative — we only remove data which we determine to be UIDs and leave the rest alone. Our system modifies request URLs instead of blocking. This aims to reduce site breakage, and enable services to collect data, provided it does not compromise the user’s privacy.
Like existing tools, we focus on removing UIDs in transmission, rather than trying to prevent UID generation. Therefore, we have three transmission vectors: HTTP Headers, URL Path, and Post data. The latter we currently do not handle as our data shows that the reach of this method is exceptionally low; however, our system allows us to continually monitor the situation, should this change.
The Ghostery anti-tracking system is split into two subsystems: One that handles only cookies, and the other which handles all other data sent in headers and the URL path.
The first anti-tracking subsystem deals with protecting users from tracking cookies. This is simple because most third-party cookies have no function beyond tracking. Therefore, we can very simply strip these from the request without breaking the page.
However, blanket third-party cookie blocking is not an ideal solution, because some third-party widgets do require cookies, to authenticate with their services, for instance.
To enable this use case, our system allows cookies in cases when user interaction with the widget is detected. When this happens, the third party is temporarily whitelisted to allow cookies.
This implementation effectively prevents all cookie tracking, and rarely breaks the user-experience on web pages. This is even though over 96% of third-party cookies are removed.
The second anti-tracking subsystem deals with the non-trivial problem of identifying whether the data sent in a request is ‘safe’ or not. By this we mean that the data point could be used as a UID, i.e. it is unique to the user.
Once we identify what data is unsafe, we remove it from the request before it is sent by the browser.
This means that if a tracker tries to aggregate their data using this UID, then all Ghostery users will appear as one, and thus gain crowd anonymity.
The algorithm therefore runs as follows:
When a page is loaded, for each third-party request, Ghostery
A UID is characterized as a value which is unique to a single user, and which is repeatedly seen by this user. Such values can be detected by aggregating the data seen by multiple users over a period of browsing time.
However, by the time this aggregation would tell us what the UIDs were, it would be too late — the trackers would already have the data. Therefore, our algorithm does the inverse: Detecting the values which cannot be UIDs and removing all other data.
The advantage of this method is that the protection for new users is available straight away. New UIDs will not be known by the system, and therefore be removed by default.
Furthermore, the set of safe values is significantly smaller than the set of unsafe. Safe values will be categorical in nature, and therefore only ever be O(1) in size, while the set of UIDs will be O(n), where n is the number of users.
We can also classify many values as safe locally, without having to consult the global safe value set. Our system uses the following rules for local classification:
(third party, key) pair, it is safe.(third party, key) pair over a two-day period, then the value is not persistent, and therefore safe.And if none of these rules can classify the value as safe, we use the global safe set, which tells us which values have achieved a quorum of users who all saw the same value.
Consider a hypothetical visit to the site example.com, which has tracker.de a third party.
After processing a request, we generate a set of T = [(s, d, k, v)] tuples as follows:
T = [
(s= example.com, d= tracker.de, k= z, v= 1459866821),
(s= example.com, d= tracker.de, k= fl, v= 21.0),
(s= example.com, d= tracker.de, k= u, v= CCAAAABI),
(s= example.com, d= tracker.de, k= vr, v= 1440x1024),
(s= example.com, d= tracker.de, k= c7, v= e9d4a7e4d2185cec),
]We can then evaluate these values:
(s= example.com, d= tracker.de, k= z, v= 1459866821): This was the first time we saw the value 1459866821 for the given (d, k), so this data is safe.
(s= example.com, d= tracker.de, k= fl, v= 21.0): The value 21.0 is too short to be a UID, so it is safe.
(s= example.com, d= tracker.de, k= u, v= CCAAAABI): More than 3 different values seen in the last two days for the same (d, k), so safe.
(s= example.com, d= tracker.de, k= vr, v= 1440×1024): Always the same value seen for this (d, k) pair, however the value is in the global safe set (as it represents a common screen resolution), therefore safe.
(s= example.com, d= tracker.de, k= c7, v= e9d4a7e4d2185cec): Always the same value seen, and not in the globally safe set, so this value is unsafe and will be removed.
We build the global safe set daily using the data sent from users’ clients. Clients collect the tuples of data from each request while browsing and send this back to us every hour, adding a timestamp parameter. The values in the tuple are hashed to prevent user-identifiable information being sent to us.
The client guarantees that a maximum of one message is sent per user per hour, so this can be used instead of a user id to count the number of users for each (third party, value) tuple. If the number of users exceeds the quorum threshold for a given hour, it is added to the safe set.
This model allows users to create this collaborative safe value set without compromising their privacy. Any privacy sensitive information in the data is obfuscated by the hash function, and, as no UID is required for our aggregation, we cannot derive any browsing history beyond the single hour granularity (there is no way to link messages from different hours), and the most information that could be gained is the first-party domain names visited.
This protection is further strengthened using our Human Web technology which further obfuscates the source of each message we receive.
The algorithmic, data-driven system for removing UIDs from third-party requests which we have described has several advantages over other anti-tracking solutions.
As an online system we can respond much quicker, and without human oversight, to changes in trackers and their techniques. If a tracking company switched domains to try and avoid blocklists, we would have the data to block this tracking within a day. Human-curated blocklists would take comparatively longer to update.
In our paper we did several tests to measure the difference between our system and other blocklist systems. Our tests indicated a reduction in breakage on web pages caused by our system, compared to adblockers.
We also saw that blocklist-based systems blocked more often, but a large proportion of these blocks were false positives: requests which did not contain any UIDs.
The downside of our method is that, unlike other blockers, we see a net performance loss when loading complex web sites. This is because other blocking systems simply block JavaScript which will then attempt to calculate and send a fingerprint, while we will block just the outgoing request with UID. Thus, blockers get a performance benefit of avoiding running this resource-heavy tracking JavaScript code.
However, we believe that in the long term, this property is a net benefit. Unlike other anti-tracking systems, Ghostery can forgive. If a tracker updates its code, and switches to a method which no longer sends UIDs, then our system will immediately stop blocking their data.
With blocklists, there is no such mechanism — trackers are then incentivized to circumvent the block (for example using a new domain name), rather than improving their data collection methods.
Our anti-tracking system has now been running successfully for over a year, blocking around 300 million cookies and removing around 10 million UIDs per day to keep our users free from tracking.
The same system, as described here, is now also available on our mobile browsers to provide the same protection across even more devices and give users control over what data third parties can collect about them.

